Our research is broadly concerned with automated undertanding of rich media, esp. pictures and language; and modeling of collective online behaviours. We specialize and innovate in different method in machine leanring and optimization, recent favorites include: stochastic time series models, sequence and language models with neural netoworks, matrix and tensor factorisation, active learning, structured prediction models.
ML for social media
- Expecting to be HIP, May 24, 2017
- Event intensity in Hawkes Intensity Processes, January 16, 2017
- Feature Driven and Point Process Approaches for Popularity Prediction, August 31, 2016
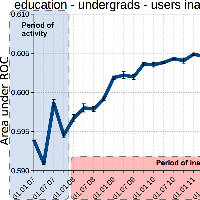
- Discussing two privacy concerns with Wikipedia, March 18, 2016
- Evolution of Privacy Loss in Wikipedia, January 16, 2017
Image + Language
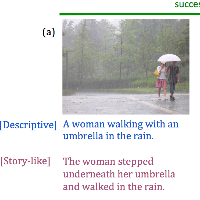
- SemStyle: Learning to Caption Images like Romantic Novels, June 10, 2018
- SentiCap: Generating Image Descriptions with Sentiments, January 3, 2016
Other projects
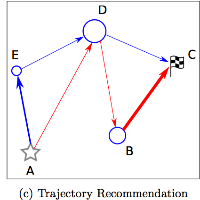
- Learning Points and Routes to Recommend Trajectories, August 31, 2016

- Visualizing Citation Patterns of Computer Science Conferences, August 18, 2016
- How Long Do Papers Survive in the Collective Academic Memory?, August 16, 2016
- Where are Ideas Coming from, and Going to? - Measuring citation flow in academic communities, July 16, 2016
- Eight Years of WSDM: Increasing Influence and Diversifying Heritage, February 22, 2016
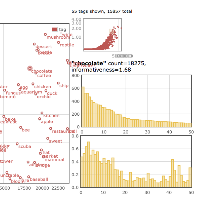
Selected topics of the recent past
Multimedia-hard problems
MM-hard refers to multimedia problems that require human-level insights and perception that can’t be realized with a single algorithmic approach. The notion of MM-hard has the potential to benefit multimedia research in two funda- mental ways. The first is to describe problems in terms of their (machine and human) difficulty; the second is to be able to do problem reduction — that is, convert one problem to another and compare problems.
Paper: IEEE Multimedia ‘14
Tracking visual memes in social media
We propose visual memes, or frequently reposted short video segments, for tracking large-scale video remix in social media. Video remixing is prevalent on social media platforms, it is part of “venacular creativity” (Burgess 2009) where users create “curated selections based on what they liked or thought was important”. Social influence are often characterized from text-based online interactions such as quoting or reweeting (Leskovec 2009). Our tool allows such metric to be developed for visual media. We found that:
- Over 50% news-related videos contain remixed content, over 70% YouTube authors participate in remixing.
- Remix probability does not correlate well with traiditional popularity metrics such as view count.
- Influence analysis on visual remix overtime can reveal content importance and user roles.
Macroscopic patterns in online news discussions
We analyze the ICWSM’11 Spinn3r dataset containing over 60 million English documents. We observe surprising connections among the 161 wikipedia events it covers, and that over half (55%) of users only link to a small fraction of prolific users (1%), a notable departure from the balanced traditional bow-tie model of web content.
Paper: ICWSM ‘12