posted by Marian-Andrei Rizoiu
Presenting our findings to the Wikimedia Community
In February 2016, Marian-Andrei was in San Francisco to present our work Evolution of Privacy Loss in Wikipedia at the WSDM'16 conference. While in San Francisco, he made contact with the Wikimedia Research, the research organization run by the Wikimedia Foundation. The folks at Wikimedia Research have a particular interest in the fields of privacy and data-driven user security, concerning both their editor and reader populations. As a result of the initial research-oriented talks, Marian-Andrei was subsequently invited to share the privacy-related insights with the broader wikimedia community at the March'16 edition of the Wikimedia Research Showcase. The talk aimed at a broader audience and it is, hence, more detailed and somewhat lighter on technical details. The talk was broadcasted on Youtube and the recording is available hereafter.
The discussion which followed the talk exposed a series of privacy-related concerns of the Wikimedia Community. In the remainder of this post, we present and try to address two of these concerns: the representativeness of the studied editor population vs. the editor disclosure bias and measures to be implemented to effectively preserve privacy.
Editor representativity vs. editor disclosure bias
The editor representativeness issue was raised by Aaron Halfaker, who is a senior researcher at Wikimedia Research and one of the first scientists to study in detail the slowdown of Wikipedia. Aaron is currently studying what makes Wikipedia editors to return to the site and he is devising recommendations for retention policies. While interested in the observations we constructed in our data profiling, especially about population trends (see next figure for some examples) he raised the issue of how representative are the studied samples for the entire editorship of Wikipedia: the disclosure bias. The disclosure bias roughly means that the subpopulation of editors that chose to disclose certain information about themselves might not be representative for the entire population. These editors might simply be less concerned with their own privacy or they might be advocates of certain causes. Disclosure bias can also affect the quality of the prediction of the personal traits for the rest of the population, since the trained models might be drawn towards this vocal and visible minority.
One solution to this problem is to perform large scale surveys within the editor population. Survey answers from a more representative part of the population could alleviate the disclosure bias and provide statistics closer to the reality of the editorship. The methodology in our paper to profile the editor population could directly be applied, should such survey data be available.
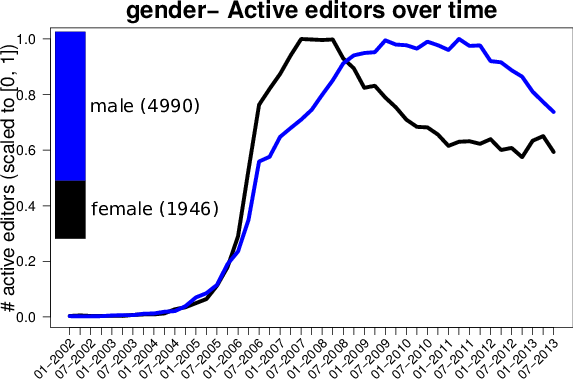 | 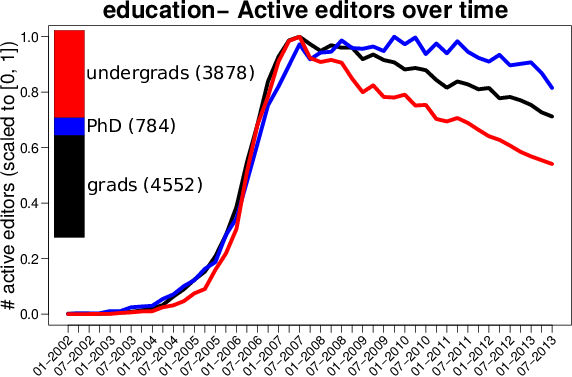 | 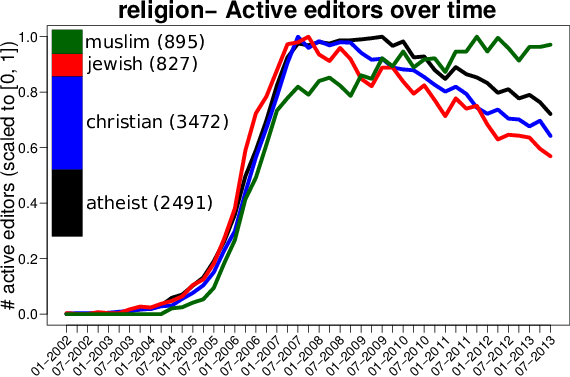 |
|---|---|---|
| The population of active editors over time, broken down by gender (left), education (middle) and religion (right). | ||
| Magnitudes for all classes are scaled from 0 to 1. | ||
| Barplots show the relative effectives of classes, absolute effectives are given in parenthesis |
What does it really mean for Wikipedia users? What measures should be taken?
This very pertinent issue was raised by Dario Taraborrelli (head of Wikimedia Research). As the legal body managing Wikipedia, the Wikimedia Foundation is obviously concerned with the effective measures that can be taken to preserve the privacy of its editors and readers. Our research was not intended to identify private information in Wikipedia, we were merely testing the hypothesis of Privacy Decay over time on Wikipedia. Unintentionally, we uncovered that the editors personal traits can be infered from their editing patterns. To the best of our knowledge, no existing studies (including our own) have shown that the real identity of Wikipedia users can be revealed based on their editing activity. However, we do not exclude that possibility if targeted methodologies are designed specifically for this purpose.
There is a growing literature on characterizing which privacy guarantees can be obtained under a given information release protocol. The solution to this concern can be both legal and technical.
We construe that one way to preserving privacy is to construct laws which would enable erasing the recorded activity in the online environment. Concepts such as k-anonymity can be used to help protect user identity in data releases. For Wikipedia, this probably means to hide historical editor activity, or at least provide an opt-out: upon request, replace (in the public Wikipedia dumps) the editor’s identifier with random noise, which should make re-identification at least harder (if not impossible).