Posted by Alasdair Tran, with edits from Lexing Xie. Thanks to Ingrid Fadelli for sending us interview questions.
In our recent paper published in CVPR 2020, we propose an end-to-end model that can generate linguistically-rich captions for news images. We also build a live demo where people can generate a caption for any New York Times article.
The Goal: Generating Interesting Captions
For many years, computers have been able to automatically generate a caption for an image. But these captions tended to be generic and uninteresting, like“a dog is barking” or “a man is sitting on a bench”. This makes us wonder, how can we generate captions that are more specific and human-like. We want to go beyond merely describing the obvious and boring visual details of an image. Our lab has already done works that make image captions sentimental and romantic, and this work is a continuation on a different dimension.
In this new direction, we want to focus on the context. In real life, most images come with a story. When you take a photo of your kid on the smartphone, there is always a personal story behind it, like a birthday party or a picnic. When you see a photo in the newspaper, there’s always an article describing the event captured in that photo. And yet somehow in most existing caption generation systems, this context is lost during the modelling process and these systems simply treat a photo as an isolated object, discarding important contextual information.
This motivated us to solve the following task: Given a news article and an image, can we build a model that could attend over both the image and the article text, in order to generate a caption with interesting information that cannot simply be inferred from looking at the image alone.
The Transform and Tell Model
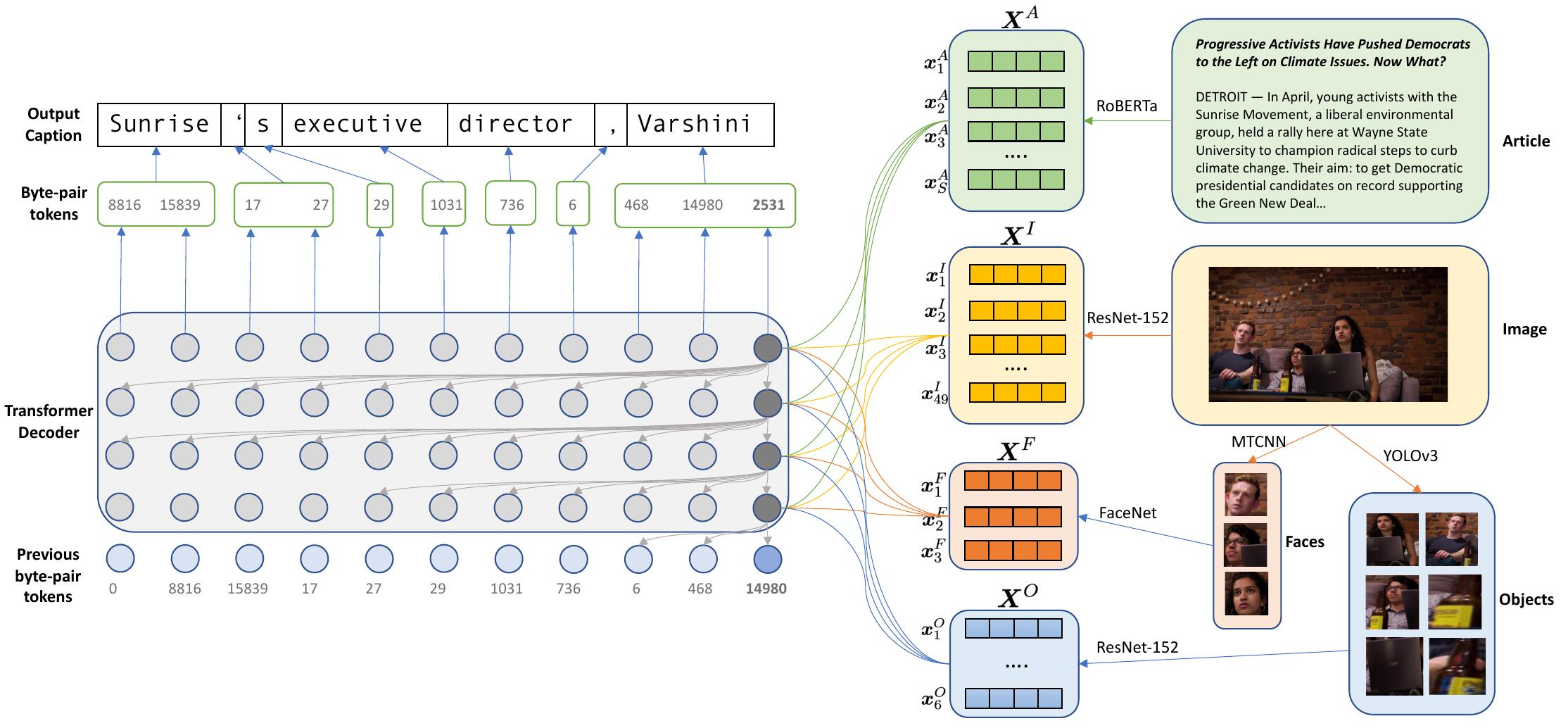
Our paper is the first to propose an end-to-end system to generate a news image caption. The key advantage of an end-to-end model is its simplicity. All we need to do is to feed the model the raw text and image, and we’ll get a caption a few seconds later. The previous state-of-the-art news captioning system had a limited vocabulary size, and in order to generate rare names, it needed two stages: generating a template such as “PERSON is standing in LOCATION”; and then filling in the placeholders with actual names in the text.
We want to skip this middle step of template generation, so we use a technique called Byte Pair Encoding, in which a word is broken down into many subparts. With this, when a model sees a rare word, it doesn’t ignore it like previous works. Instead it can generate any word (1.1 million unique words in our NYTimes 800K dataset) using only about 50,000 subwords.
We also observe that in previous works, the captions tended to use simple language, like it was written by a school student instead of a professional journalist. We found that this was partly due to the use of a model architecture called LSTM (Long Short Term Memory). LSTMs have been used extensively in sequence modelling, but it has the disadvantage of forgetting the beginning of very long sequences and being quite slow to train. In recent years, other researchers have used a new architecture called Transformers to achieve state-of-the-art results in many tasks such as language modelling and machine translation.
Impressed by this progress, we adapted the transformer architecture to our image captioning task and showed that it can generate captions that are linguistically much richer than LSTMs. One key algorithmic component that enables this leap in natural language ability is called the attention mechanism, which explicitly computes similarities between any word in the caption and any part of the contexts (which can be the article text, the image patches, or faces & objects in the image). This is done using functions that generalise the vector inner products.
Finally, one feature that distinguishes new images from other types of images is that they heavily feature people. In particular, we found that in New York Times, about three-quarter of all images contain at least one face. This inspired us to add two specialised modules in our model, one focusing on detecting faces while other focuses on detecting objects. This addition improves the accuracy of the generated entity names, especially people’s names, in the captions.
Practical Implications
Getting a machine to think like humans has always been an important goal in Artificial Intelligence. We were able to take one step closer to this goal by building a model that can incorporate real-world knowledge about names in existing text. The model can read a long piece of text and be able to know which parts are important to the image it wants to caption.
Furthermore the generated captions can imitate the writing style of the New York Times. Human languages contain a lot of ambiguity and idiosyncrasies. Being able to build a model that can capture some of this linguistic richness is very impressive.
Further Research

The model that we have so far can only attend to the current article. However when we look at a news article, we can easily connect the people and events mentioned in the text to other people and events that we have read about the past. One future direction would be to give the model the ability to also attend to other similar articles, or to a background knowledge source such as Wikipedia. This will give the model a richer context, allowing it to generate more interesting captions.
We would also love to explore the reverse task, where instead of writing captions, the model would pick an appropriate image from a large database of images to illustrate a news article. Furthermore, the attention mechanism can even be used to choose where in the article the image should be placed. This would hopefully help content creators speed up the publishing process.
Another future direction would be to take the transformer architecture that we already have and apply it to a different domain such as writing longer passages of text or summarising related background knowledge. The summarisation task is particularly important in the current age due to the vast amount of data being generated everyday. One fun application would be to have the model attend to new arXiv papers and suggest interesting content for scientific news releases like this article being written!
Resources
Alasdair Tran, Alexander Mathews, Lexing Xie. Transform and Tell: Entity-Aware News Image Captioning, in the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, 2020.
| Download: | Abstract | Paper+supplement PDF |
|---|---|
| Code | Project page | Github repository |
| Bibtex: |
@InProceedings{Tran2020Tell,
author = {Tran, Alasdair and Mathews, Alexander and Xie, Lexing},
title = {{Transform and Tell: Entity-Aware News Image Captioning}},
booktitle = {The IEEE Conference on Computer Vision and Pattern Recognition (CVPR)},
month = {June},
year = {2020}
}