Posted by Lexing Xie and Lydia Lucchesi.

Data preprocessing is a crucial intermediate stage in quantitative data analysis. During this stage, data practitioners decide how to resolve dataset issues and transform, clean, and format the dataset(s). It can be a challenging stage, full of decisions that have the potential to influence analytical outcomes. Yet, data preprocessing is often treated as behind-the-scenes work and overlooked in research dissemination. This discrepancy, in the practice and presentation of data analytics, is limiting when it comes to replicating, interpreting, and utilising research outputs.
The two central contributions in Lydia’s 2024 PhD Thesis are Smallset Timelines and the smallsets software. The Smallset Timeline is a static and compact visualisation, documenting the sequence of decisions in a preprocessing pipeline; it is composed of small data snapshots of different preprocessing steps. The smallsets R software builds a Smallset Timeline from a user’s data preprocessing script, containing structured comments with snapshot instructions. Together, they are designed to support the production of accessible data preprocessing documentation.
This post illustrates these contributions with four examples, along with an example notebook that produces them.
- Ebirds data in citizen science
- HMDA homeloan data, reflecting nuances in defining and reporting on race
- The folktables dataset for machine learning, on fairness in income classification
- NASA software defect data
We will conclude this overview with an example notebook to illustrate the ease of using smallsets in exisitng data-preprocessing code, along with an FAQ.
Example 1: Ebirds Data in Citizen Science
We examine the eBird database, a citizen science program with millions of bird sightings from across the globe [Sullivan et al., 2009]. Citizen scientists upload their bird sightings, by completing an eBird checklist form. The form collects information about every bird observed during an observation period. As noted on the eBird website,7 to date the eBird data has been used in over 930 publications.
Johnston et al. [2021] recommend a series of best practices for using citizen science data. These recommendations are based on an eBird case study that explored the effects of different data preparations on statistical inference. The authors found that the combination of using complete checklists only, spatial subsampling, effort filters,8 and effort covariates produced the strongest modelling result. As a supplement to the study, Strimas-Mackey et al. [2023] produced the guide “Best Practices for Using eBird Data,” which provides a step-by-step implementation of the study’s recommendations in the R programming language.

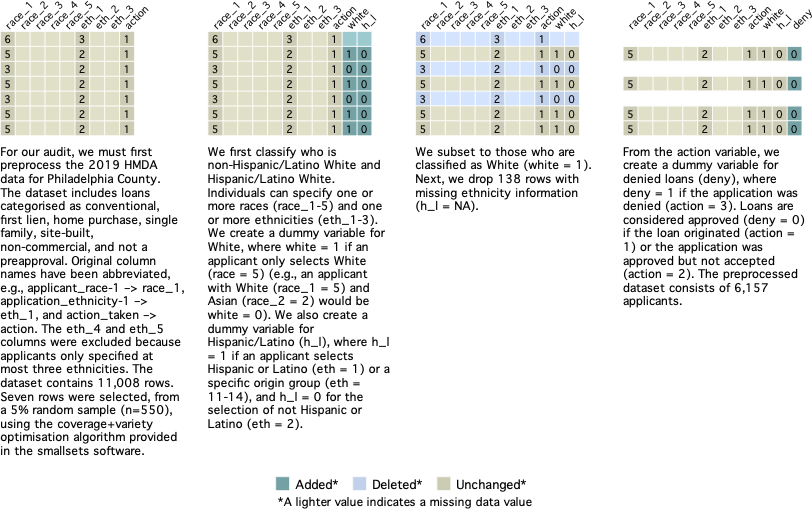
Example 2: HMDA Homeloan Data - Nuances in Defining and Processing Race
In 1975, the United States (U.S.) Congress passed the Home Mortgage Disclosure Act (HMDA), mandating that data about home lend- ing be made public. Since then, HMDA data have become a valuable resource to understand the lending market and audit lending bodies for discriminatory practices [McCoy, 2007].13 It is illegal in the U.S. to deny an applicant a home loan on the basis of race or color, national origin, religion, sex, familial status, or handicap [Fair Housing Act]. Auditing with the use of HMDA data, however, is not a straightforward task. Rather, it requires careful examination of the data and difficult decisions about how to best use it [Avery et al., 2007].

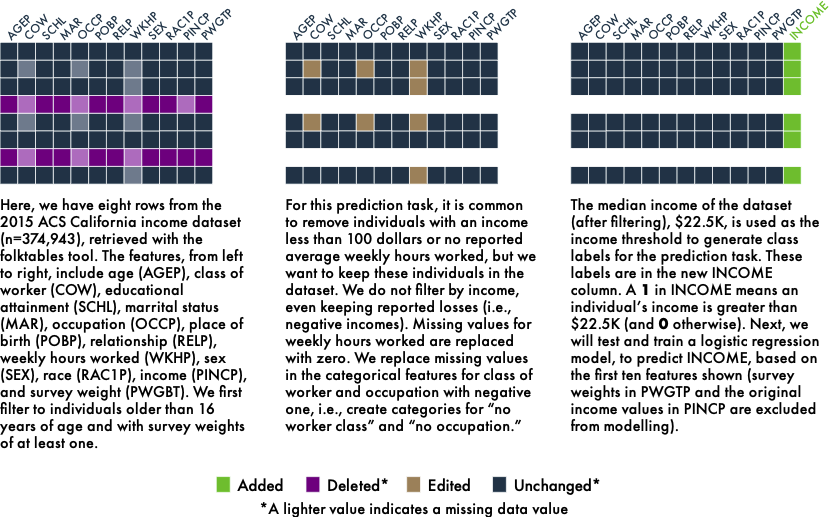
Example 3: Examining Fairness of Income Classification in the folktables Dataset for Machine Learning

Example 4: A widely-used dataset of software defects
In the early 2000s, the NASA Metrics Data Program (MDP) released 13 datasets for software defect detection, which involves developing algorithms to predict bugs in source code.

Example notebook for the fairness example
the Jupyter Notebook fairness analysis.ipynb, for the scenario described in Example 3, in which smallsets is integrated into a folktables workflow. The second code cell contains a Python preprocessing function, documented with smallsets structured comments.


FAQ (detailed answers coming soon, new questions most welcome)
- Is smallsets cutomizable? Yes, please see this detailed user guide.
- Will smallsets automate data-preprocessing? In short, no.
- Is Python code supported? Yes, in ipython notebooks.
- Will smallsets support preprocessing code across different scripts? Not yet.
- Will smallsets support word embeddings, large language models and the like? Not yet, let us know what you think are important to support.
Resources
- Smallset Timelines: A Visual Representation of Data Preprocessing Decisions, Lydia R. Lucchesi, Petra M. Kuhnert, Jenny L. Davis, and Lexing Xie, Proceedings of the 2022 ACM Conference on Fairness, Accountability, and Transparency, 2022
- Visualisation and Software to Communicate Data Preprocessing Decisions, Lydia R. Lucchesi, PhD Thesis, The Australian National University, 2024