posted by Swapnil Mishra
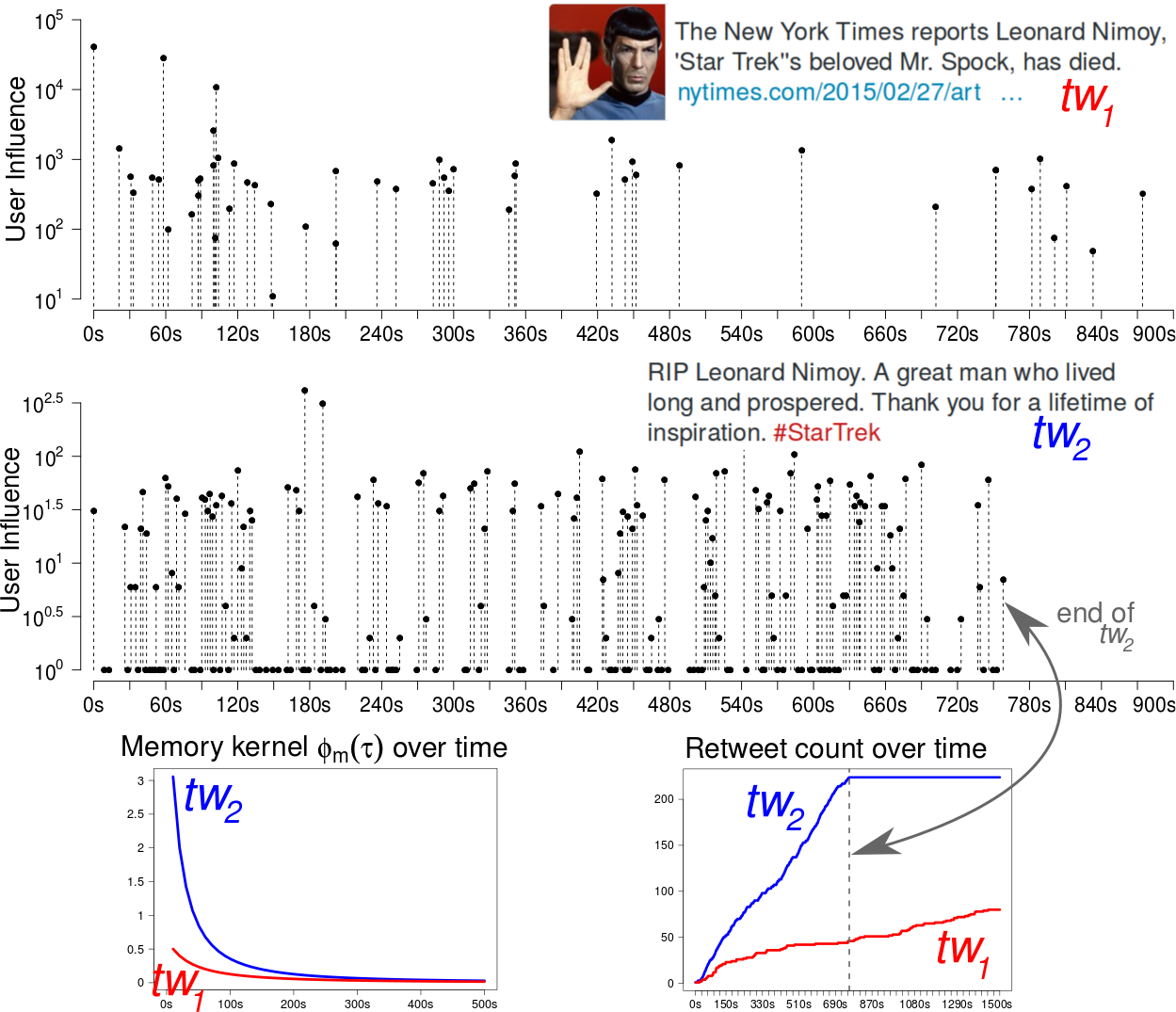
Predicting popularity as number of retweets a tweet will get is an important and difficult task. It’s unclear which approaches, settings and features works best. Our current CIKM ‘16 paper bridges this gap by comparing across feature driven and point process approaches under both regression and classification settings.
The problem
Predicting popularity on social media has gathered a lot of attention, as it helps both content users and producers to cope with information overload. A lot has been done in this space from predicting whether a cascade will double it’s size, whether an item will have 10 million views or total number of views/retweets a particular post will gather. People have gone from trying a variety of features learned from a full network data (hard to get barring some) to using stochastic processes to model the event time data. But it’s still unclear which features generalizes over different settings, whether two different class of approaches be compared on same dataset. Also a lot of this work is done on proprietary data so it becomes hard to replicate or generalize over a new setup.
Our Solution
In our work, we address these challenges in context of predicting final size of a retweet cascades as follows:
- We build a generative model with Hawkes Process, which has a predictive layer on top, using model parameters as features, to make final size prediction. The properties modeled into the generative model are: inherent quality of the tweet, social influence of users and the length of “social memory”.
- We develop a state of the art feature driven approach, where features can be computed on data containing solely the message content and basic user profiles. Hence these features can be computed very easily on any social dataset.
- We further combine both models to create a new hybrid model, which shows superior results.
- We use all three models to do both regression (actual number of retweets) and classification (whether a cascade will double it’s current size) task.
- Finally we release a public dataset that can be used for benchmarking both feature driven and generative models.
We conclude from our observations that hence further popularity prediction studies should compare the results across both class (predictive and generative) of methods in both regression and classification tasks.
Sample results
Absolute Relative Error(ARE) is evaluated as the ratio of difference between predicted size and real size to the real size of a cascade. For regression task lower the ARE better is the performance.
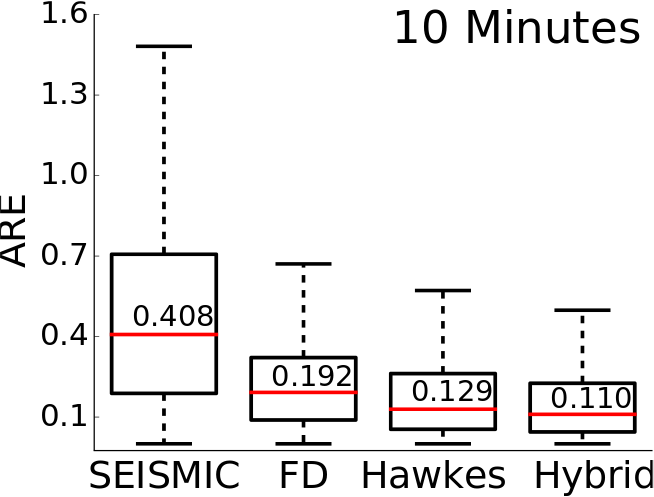
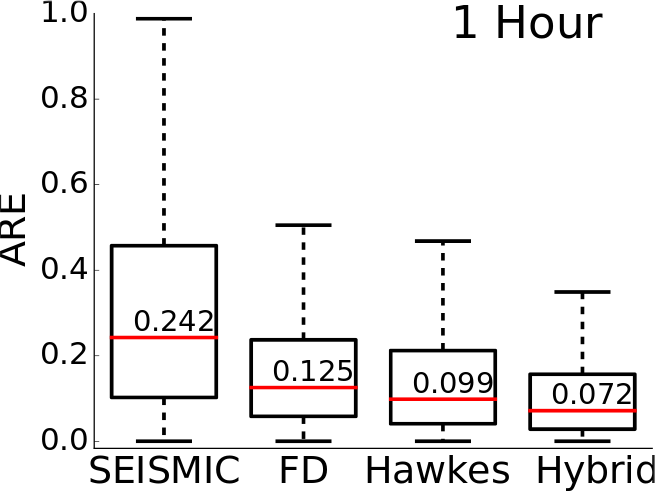
Distribution of ARE on the News dataset, split in time for July, for Seismic, Feature-Driven(FD), Hawkes and Hybrid, after observing 10 minutes (left) and 1 hour (right). The (red line) and the numeric annotations denote median value. Feature-Driven, Hawkes and Hybrid reduce median ARE by atleast 200%.
The results for classification task is presented in table below. Accuracy (standard deviation) when predicting whether a cascade will double its size or not after reaching 25 tweets and 50 tweets. The generative-based classifier HawkesC(classification version of Hawkes models) improves substantially over the baseline of random guess, however Feature-Driven has the best prediction accuracy.
| Approach | 25 tweets | 50 tweets |
|---|---|---|
| Random Guess | 0.52 | 0.53 |
| HawkesC | 0.66(0.013) | 0.70(0.009) |
| Feature-Driven | 0.79(0.009) | 0.81(0.011) |
| Hybrid | 0.79(0.008) | 0.82(0.013) |
Resources
Swapnil Mishra, Marian-Andrei Rizoiu and Lexing Xie. Feature Driven and Point Process Approaches for Popularity Prediction, in Proceedings of the 25th ACM International Conference on Conference on Information and Knowledge Management (CIKM ‘16), Indianapolis, IN, USA.
| Download: | Paper PDF + SI Presentation |
| Data: | NEWS Dataset |
| Bibtex: |
@inproceedings{Mishra2016,
title = {{Feature Driven and Point Process Approaches for Popularity Prediction}},
author = {Mishra, Swapnil and Rizoiu, Marian-Andrei and Xie, Lexing},
booktitle = {Proceedings of the 25th ACM International Conference on Information and Knowledge Management},
series = {CIKM '16},
address = {Indianapolis, IN, USA},
doi = {10.1145/2983323.2983812},
year = {2016}
isbn = {978-1-4503-4073-1},
pages = {1069--1078},
numpages = {10},
publisher = {ACM},
address = {New York, NY, USA},
keywords = {cascade prediction, information diffusion, self-exciting point process, social media}
}