Posted by Lexing Xie and Ziyu Chen.
Thanks to Eric Byler for a 2022 profile article in college news!
We identify Reddit’s Am I the Asshole (AITA) forum as a rich source of data to investigate the moral sphere using AI and machine learning. This work is done with Josh Nguyen and Alasdair Tran, and ANU philosophers Colin Klein, Nick Carroll, and most recently Nick Schuster.
Question 1: what are in the 100,000 moral dilemmas?
The popular online community AITA crowd-sources moral deliberation one sticky situation at a time, they have accumulated 100,000+ dilemmas since 2013. We ask: what are the types of issues people struggle with?
Surprise 1: There are ~50 topics, and people percieve them in pairs.
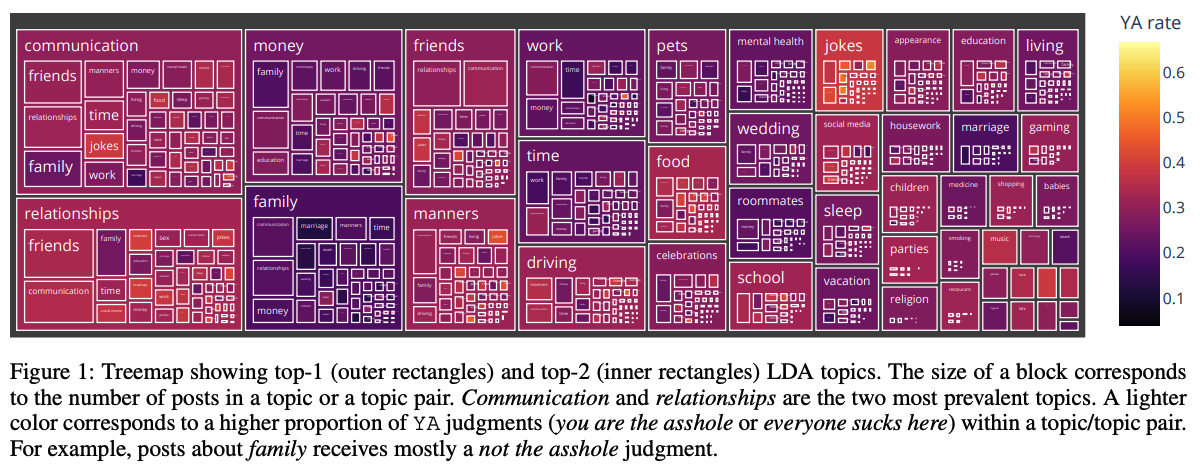
We analysed 100,000 threads—the largest such study to date—using algorithms to identify topic clusters. Human participants helped to refine the algorithm by deciding when to combine similar clusters and how to assign thematic designations to threads. The resulting data identifies 47 meaningful topics that fall into five meta-categories: Identities, Aspects, Processes, Events, and Things. Aspects, for example, includes such topics as hygiene, manners, and safety while Events includes weddings, breakups, and parties. The paper explains that clustering algorithms were designed to allow clusters to overlap, “since both the intersections and the gaps between two intuitive clusters (such as family and money) may be meaningful and interesting”. We found that most moral dilemmas included combinations of topics called topic pairs. Frequently occurring topic pairs included friends & manners, communication & mental health, and celebrations & manners. There are about 1,000 significant top pairs, which adds nuance beyond what can be described with the 47 topics alone.
“Most philosophers distinguish between moral norms, such as the norm that we ought to keep our promises, and conventional norms, such as the norm that we ought to allow passengers to exit a busy train before we try to board it”, Nick Carroll said. “This has resulted in philosophers excising from the realm of morality various dilemmas that fall on the conventional side of this distinction. But by contrast, the dilemmas that non-philosophers on AITA post about are mostly about what philosophers would consider conventional norms—dilemmas relating to, for instance, communication, family, friends, manners, and relationships. The realm of morality is far larger than philosophers ordinarily think it is.”
Question 2: How do we measure moral dimensions in lots and lots of written text?
Studying moral content online is a topic area with growing interest.
Many online discussions have a tendency to reflect aspects of morality, and
researchers thus far have aimed to study how and to what
extent moral dimensions vary throughout this vast domain.
At the scale of AITA for example (100,000+ posts with up to a few hundred words each), manual inspection is obviously out of the question, so what shall we do?
One popular approach is to use a subjective lexicon, i.e. counting relevant words. Moral foundations theory is a taxonomy of intuitions widely used in data-driven analyses of online content, and there has been several lexicon built by different teams for it. A closer examination of three such lexicon gave us a surprise:
Surprise 2: There is very little agreement among linguistic resources curated for the same five moral foundations
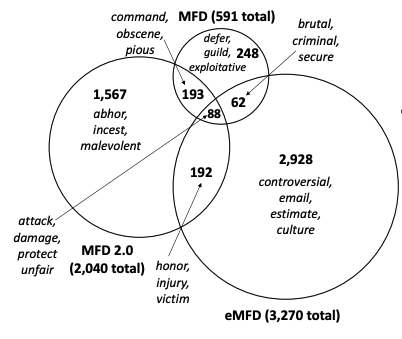
In this work, we fine-tune a large language model to measure moral foundations in text based on datasets covering news media and long- and short-form online discussions. The resulting model, called Mformer, outperforms existing approaches on the same domains by 4–12% in AUC and further generalizes well to four commonly used moral text datasets, improving by up to 17% in AUC.
Pretrained model and datasets are released publicly. We posit that Mformer will help the research community quantify moral dimensions for a range of tasks and data domains, and eventually contribute to the understanding of moral situations faced by humans and machines.
FAQ (answers will be posted soon)
- Don’t you want to build an AI that make moral judgements? In short, no.
- What are some of the limitations of AITA?
- Is Moral Foundations the De Facto tool then?
Resources
- Mapping Topics in 100,000 Real-life Moral Dilemmas, Tuan Dung Nguyen, Georgiana Lyall, Alasdair Tran, Minjeong Shin, Nicholas George Carroll, Colin Klein, and Lexing Xie, International AAAI Conference on Web and Social Media (ICWSM ‘22), 2022
- Measuring Moral Dimensions in Social Media with Mformer, Tuan Dung Nguyen, Ziyu Chen, Nicholas George Carroll, Alasdair Tran, Colin Klein, and Lexing Xie, International AAAI Conference on Web and Social Media (ICWSM ‘24), 2024